Dancing with Models
Dancing with Models
Decision-support environmental modelling must accomplish two important tasks. These are:
- Quantification of the uncertainties of decision-critical predictions;
- Reduction of these uncertainties through assimilation of available data, particularly measurements of present and historical system behaviour.
Obviously, a numerical simulator cannot perform these tasks on its own. Hence numerical simulation of environmental processes, on its own, cannot support environmental management. Instead, simulators must be used in conjunction with software that can run them many times in order to perform these important tasks.
Two specifications are fundamental for model partner software. These are:
- A non-intrusive interface with a model;
- The ability to undertake model runs in parallel.
The PEST and PEST++ run managers satisfy both of these specifications. But before discussing this further, let us talk about what constitutes “a model”.
A Numerical Model
When used for decision support, a numerical model must be linked to the real world. These linkages are normally provided by utility programs that run before it and after it as pre-processors and post-processors. All of these programs must be run in succession - by a modeller or by PEST. This happens automatically if the commands to run individual model components are placed in a batch or script file.
Pre-processors are often used for model parameterization. For a spatial model such as a groundwater model, parameterization can be zone based, pilot point based, or model cell based. Other parameterization options are also available. If parameterization is at least partially pilot point based, then a model pre-processor must undertake spatial interpolation from the locations of pilot points to the locations of model cells.
Post-processors are often used to undertake spatial and time-interpolation of system states calculated at model cells to the locations and times at which field measurements were made. It is the job of model dancing partners such as PEST to adjust a model’s parameters until space- and time-interpolated model outputs match these field measurements. However often the history-matching process requires more sophistication than this. Often strategically-defined functions of field observations (for example temporal and spatial differences) should be matched with the same functions of model outputs. If this is done in a clever way it can reduce, or eliminate, parameter and predictive bias that often attends careless history-matching. It is the task of model post-processors to calculate the functions of model outputs which must be matched to the functions of field measurements on each occasion that the model is run.
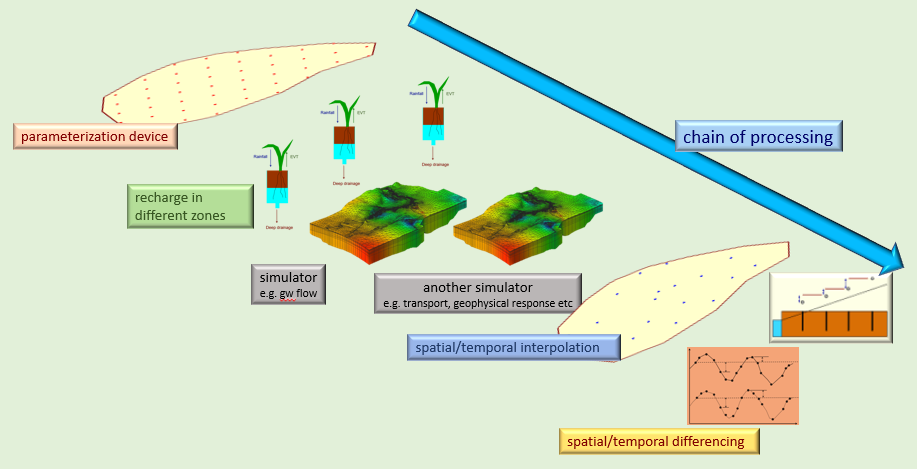
All of this has implications for model dancing partners. The “model” that they must run repeatedly as its parameters are adjusted to match historical measurements of system state is actually a compendium of programs. Presumably each of these programs has input files that it must read and output files that it must write. The values of model parameters reside on one or more of these input files. The values of model-calculated counterparts to field measurements are written to one or more of these output files.
Non-Intrusive Model Interface
PEST (and other dancing partners of the PEST suite) can communicate with a model of arbitrary complexity through the model’s own input and output files. Before it runs a model, PEST populates model input files with parameter values which it would like the model to use on that particular run. When the model has run to completion, PEST reads user-specified numbers from pertinent model output files which it then compares with field-measured counterparts. When preparing for a PEST run you, the user, must teach it how to write and read model files. Template files of model input files are used to pass parameters to a model. Meanwhile, model output files are read using special instructions. You can prepare template and instruction files yourself using a text editor. Alternatively, utility programs supplied with the PEST suite can write these files for you.

Use of a non-intrusive model interface has important repercussions. These include the following:
- You don’t need the model’s source code in order to use PEST with a model;
- A model can be arbitrarily complex, and still interact with PEST;
- A user has ultimate flexibility in how he/she designs a model’s parameterization scheme, and how he/she post-processes model outputs before matching them with field measurements.
These are all essential requirements of modern-day decision-support modelling. They make data assimilation and uncertainty quantification the focus of this type of modelling – exactly as it should be.
Model Run Parallelization
These days, the capacity to parallelize model runs exists:
- on a single desktop computer or laptop;
- over desktop computers comprising an office network;
- on high performance computing clusters;
- on the cloud.
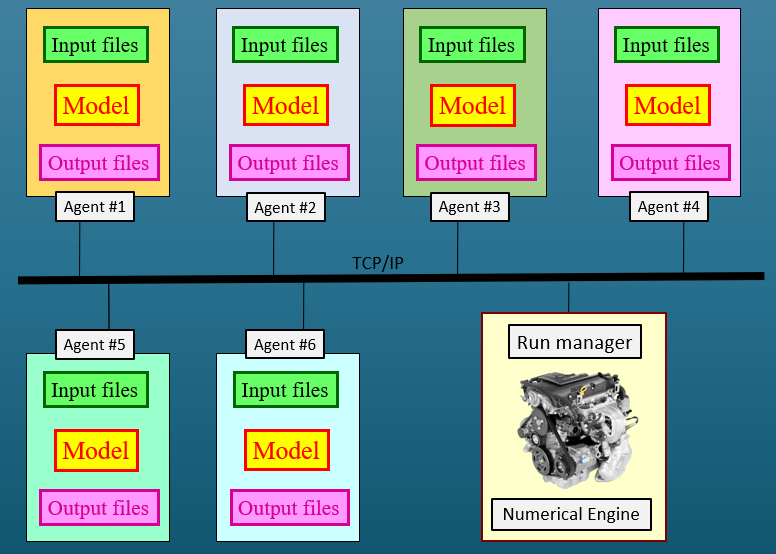
PEST-suite model dancing partners can operate in all of these computing environments. Each of them employs a run manager that can communicate with so-called “run agents”. You can use as many agents as you wish. These can run on the same or different computer as that on which the run manager is operating. The manager and agents communicate with each other using TCP/IP (the language of the internet).
When the manager wants a model run carried out, it sends to the fastest available agent the set of parameters which it would like the model to use on that run. The agent writes input files for the model on its local machine using local copies of template files. It then runs the model. When execution of the model is complete, the agent reads model output files using local copies of instruction files. It sends what it reads back to the manager.